别人都在卷Harness, 而Google 的沉默振聋发聩
Google在做什么?
今年1月,Google Gemini API团队的Principal Engineer Jaana Dogan在X上发了一条帖子,迅速获得了数百万次浏览。
“我不是在开玩笑,这也不好笑。我们在Google从去年起就一直在尝试构建分布式agent编排系统,各种方案,团队内部意见不统一。我给Claude Code描述了这个问题,它在一个小时内生成了我们花了一年时间构建的东西。”
她后来补充说,生成的只是一个玩具版本,不是生产级代码。但她同时说了一句话,“我们不能一边要求人们100%发挥,一边让他们不断在冲突和争论中消耗。”
三个月过去了,这条帖子背后的问题变得更加尖锐。据开发者调查数据,Claude Code在专业开发者中拿下约41%的市场份额,年化收入约25亿美元,是AI编程工具领域有史以来增长最快的产品。OpenClaw两个月内从开源项目迅速走红为全球热议的agent平台,中国大厂飞书、钉钉、微信纷纷接入。“Agent Harness”成为AI行业最新、最热的关键词。
而过去这一周的密度更是惊人。Anthropic宣布年化收入run rate突破300亿美元(2025年底为90亿),同时发布了Claude Mythos Preview,一个比现有Opus更强的新层级前沿模型,以Project Glasswing的名义定向开放给Palo Alto Networks、Amazon、Apple等40家机构用于网络安全防御,消息发布当天引发美国软件股集体下跌。同一周还上线了Claude Managed Agents,为企业提供托管的agent基础设施,从沙盒到编排一站式解决。
Meta发布了Muse Spark,Alexandr Wang领导的Meta Superintelligence Labs的第一个模型,放弃了此前坚持的开源路线,转向闭源。OpenAI不久前刚完成1220亿美元融资,估值8520亿美元,Codex周活跃用户超过200万且仍在快速增长。
而Google,在这一切中几乎没有声音。
1、强模型,弱Harness
Ben Thompson在今年3月的文章中点出了Google的核心问题,Gemini 是一款强大的模型,但谷歌尚未为其推出有说服力的Harness。(Gemini is a strong model, but Google hasn't yet shipped a compelling Harness)。
所谓Harness,是围绕AI模型构建的编排和控制层,让模型不只是在聊天框里回答问题,而是能在真实场景中稳定地执行多步骤、跨应用的复杂任务。Thompson的判断是,agent时代的竞争关键已经从模型本身转移到了Harness。他用苹果的硬件-软件整合做类比,利润从模块化的、被商品化的部分流走,流向整合的、差异化的部分。
Anthropic的Claude Code和OpenAI的Codex建立了模型与Harness的紧密整合。Google没有。
Google的agent产品并不少。Jules是自动编程agent,Antigravity是Google以24亿美元从Windsurf挖来CEO Varun Mohan等核心人才后组建的agentic coding平台,Gemini Code Assist在IDE里有agent模式,协议层面有A2A和ADK等开发者框架。消费端还有Gemini Agent,能帮用户管理邮件、日历、执行多步骤任务,不过目前只对美国的Ultra用户开放,月费249.99美元。
但市场数据说明了一切。Antigravity的开发者采用率与Claude Code差距明显。不少用户选择在Antigravity内切换到Claude的模型来获得更好的编程效果。Composio的对比测试中,同一个任务Claude Code用了1小时17分钟自主完成,Gemini CLI用了2小时2分钟且需要人工干预,过程中“会陷入循环,反复尝试相同的方法”。
Hacker News上一个高赞帖子标题写着,Google在agentic CLI coding方面远远落后。How-To Geek的评测说,“我两个都大量使用过,根本不是一个量级的竞争。”
连Hassabis本人也在金融时报采访中承认,Claude Code“做了一些特别的东西”。
这个gap到底是主动选择还是被动落后?
Dogan的帖子给出了一个很难回避的答案。“各种方案、团队意见不统一”,这指向的不是战略取舍,而是组织执行力出了问题。Antigravity上线后留不住想用Gemini写代码的用户,Jules在公测阶段的数据(228万次访问、14万次代码改进)和Claude Code的增长曲线不在一个量级。这些不是选择不做能解释的,是做了但没做好。
皮查伊和Hassabis的公开发言试图把这呈现为一种优先级选择,强调Google的资源倾斜给了模型训练和TPU扩产,“先模型、再产品”。但当你自家的Principal Engineer公开说Claude Code一小时干完了团队一年的活,这个战略选择的说法就不那么有说服力了。
2、Gemini在打另一场仗
把Harness gap等同于“Google在AI上失败了”,是把问题简单化了。Harness gap是开发者工具这个特定赛道上的缺位,不是消费端的溃败。事实上,如果你只看消费者数据,Google的AI业务看起来相当健康。
Gemini的消费端数据依然强势。月活7.5亿,据Apptopia数据,在美国AI聊天应用的市场份额从14.7%增长到约25%,网页月访问量突破20亿次。
App Store排名上,Meta AI因Muse Spark发布冲进前十,Gemini仍然稳居第3,仅次于ChatGPT和Claude。
今年3月Google的产品更新节奏不慢。Gemini 3.1 Flash-Lite(Google主打高吞吐低成本的轻量模型)、Gemma 4开源模型(基于Gemini 3架构,Google在开源生态的一次重要押注)、Workspace全家桶AI深度整合、NotebookLM持续迭代、Gemini Live对话体验升级、Pixel手机上的Gemini App Actions开始支持跨应用操作。
只是这些更新的方向和行业热点大部分错开了。行业在讨论agent Harness和coding工具,Google在做搜索整合、Workspace生产力、手机助手。
Gemini API的定价整体低于Claude和GPT等闭源模型(具体随型号差异较大),且提供慷慨的免费额度,不过和DeepSeek等开源模型比,价格优势就不那么突出了。开发者社区形成了一种务实的分工,高价值项目用Claude Code,追求性价比用Gemini、开源模型。超过75%的企业组织已经在生产环境中使用多个AI供应商。
皮查伊在最近一次播客中说,搜索团队为每个子功能设定了毫秒级的延迟预算。Flash模型达到Pro的90%能力,速度快得多。他说这完全不是一个“零和博弈的时刻”。
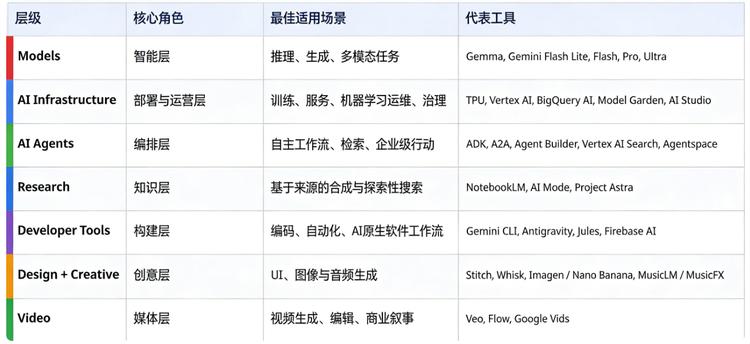
Google优化的是十亿级用户的轻量体验,搜索、Gmail、YouTube、Android,每一毫秒都在考量范围内。这个方向在过去二十年一直是对的。
但agent时代的逻辑可能不同。Claude Code之所以引爆讨论,恰恰因为它是一个独立的产品,有自己的入口和体验。OpenClaw之所以爆发,是因为它构建了一个独立的平台。如果Harness层成为下一个平台级入口(就像搜索之于网页、App Store之于移动端),Google在这一层的缺位就不只是不参与某个细分市场的问题了。
3、庄家不需要站在台前
以上说的都是产品层面的事。但Google这家公司有一个其他AI公司不具备的特殊身份,它同时是AI行业最大的基础设施供应商之一。就在Anthropic发布Mythos、Meta推出Muse Spark的同一周,Google这边的大新闻不是某个产品发布,而是一份TPU算力合同。

Anthropic和Broadcom、Google在4月初正式确认了一份长期协议,从2027年起锁定约3.5GW下一代TPU算力,据Broadcom披露文件显示合同延续到2031年。此前Anthropic已经在执行另一份价值数百亿美元的合同,最多100万颗TPU,2026年上线超1GW算力。
两份合同叠加,Anthropic的核心算力在未来五六年相当程度上绑定在Google的基础设施上。Claude Code越成功,Anthropic需要的算力越多,Google Cloud收到的账单就越大。
OpenAI也在用TPU。2025年年中开始通过Google Cloud租用TPU降低推理成本,推理目前占OpenAI算力预算的一半以上。Meta在2026年2月放弃自研AI芯片Iris和Olympus,转投TPU。
SemiAnalysis指出了一个耐人寻味的现象,OpenAI甚至还没有大规模部署TPU,但仅仅是拥有“可能转向TPU”这个选项,就从Nvidia拿到了约30%的折扣,他们称之为“威胁折扣效应”。TPU的存在本身就在重塑AI算力市场的定价权。
SemiAnalysis对TPUv7(代号Ironwood)的评估是,性能与Nvidia Blackwell大致相当,但每有效FLOP的总成本低20%到50%。
当然,TPU的护城河也不是没有挑战。Anthropic同时在用TPU、Amazon Trainium和Nvidia GPU三条腿走路,OpenAI有自研芯片的长期计划,Amazon的Trainium在追赶。但至少在目前,TPU的客户名单还在变长,不是在变短。
皮查伊在播客中说他每周至少花一个小时管理TPU的项目分配,“按项目和团队了解他们所使用的计算单元”。CEO亲自管芯片,这件事本身就说明了在Google的优先级里,算力远比产品层的开发者心智更接近核心。
投资布局上,Google持有Anthropic约14%的股份、SpaceX的股份(SpaceX在2026年2月收购xAI后,Google间接持有xAI相关资产)。AI赛道的头部玩家,Google要么自己做,要么持股,要么卖算力。
Google在科学和前沿技术方向的储备也不应被忽略。Hassabis和Jumper凭AlphaFold2获得了2024年诺贝尔化学奖,Isomorphic Labs在做AI药物发现,Genie 3在探索交互式世界模型,机器人基础模型在和Boston Dynamics合作,Waymo已经在多个城市运营无人出租车。这些和当下agent热潮没有直接关系,但构成了Google独有的技术纵深。
4、不一样的AI路径
4月22日,Google Cloud Next在拉斯维加斯开幕(美西时间)。5月19-20日,Google I/O紧随其后。官方预告已经明确提到"agentic coding和最新Gemini模型更新"。接下来六周是Google集中亮牌的窗口。
但即便Google在这两个会上发布了有竞争力的agent产品,它走的也注定是一条和OpenAI、Anthropic不同的路。
过去这一周的行业动作说明了一件事,所有玩家都在积极调整AI战略。Anthropic用Claude Mythos把前沿模型能力打包成了面向安全行业的定向产品方案,这种把模型能力快速产品化到特定高价值场景的动作,是Google目前缺少的。Meta发布Muse Spark时放弃了坚持多年的开源路线,转向闭源,试图用30亿月活用户的分发优势追赶。OpenAI在推“AI超级应用”的概念,把ChatGPT、Codex和浏览能力统一成一个agent-first的入口。
每家公司都在抢位置,Google的相对沉默在这个背景下格外显眼。
综合皮查伊和Hassabis近期的公开发言,Google的AI战略逻辑比较清楚,不把AI当作一个独立的产品类别来经营,而是当作整个公司的加速器。皮查伊的原话是,“我们拥有这项通用技术,它可以加速所有业务的发展,搜索、YouTube、Cloud、Waymo。”Hassabis的KPI排序是先模型做到最好,然后尽快反映到产品中。
这和OpenAI、Anthropic的路径完全不同。OpenAI围绕ChatGPT建立了独立的消费者入口,然后向企业和开发者两端延伸。Anthropic围绕Claude Code建立了开发者工具壁垒,再通过API和企业服务变现。两家公司的共同点是都在做独立的AI产品品牌,争夺用户的直接注意力。
Google赌的是,长期来看模型会商品化,agent产品会反复迭代和替换,但算力基础设施和十亿级分发渠道(搜索、Android、YouTube、Workspace)不会轻易被替代。与其在产品层和一堆初创公司逐个厮杀,不如守住基础设施和分发,等产品层面的格局明朗了再出手也不迟。
这个赌注是否正确,取决于一个关键假设,Harness层不会成为一个锁定用户的平台级入口。如果agent只是工作流的一部分,用户会在Claude、Gemini、GPT之间灵活切换,那Google的“基础设施+分发”路径就是对的,不需要在Harness上赢。
但越来越多的迹象显示,agent正在演变成一个操作系统级别的界面。Claude Managed Agents已经在做这件事,Harness正在从产品概念变成基础设施。那Google就可能在拥有最好的模型和最强的芯片的情况下,依然错过这个时代最重要的产品窗口。这不是没有先例的。Google曾经在即时通讯、社交网络等领域拥有很强的技术基础,但在这些领域的产品竞争中并不总是赢家。
Gemini 3在模型层证明了Google不会缺席。TPU在基础设施层证明了Google无论如何都会赚钱。真正悬而未决的是第三层,agent Harness。Google Cloud Next和I/O或许会给出第一批线索。
全部评论